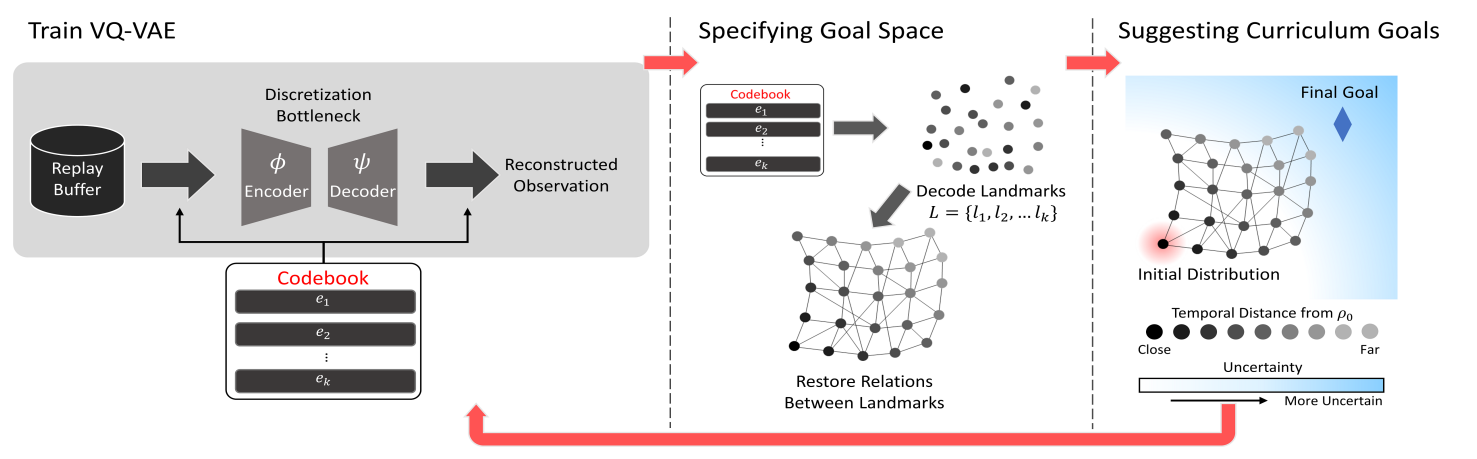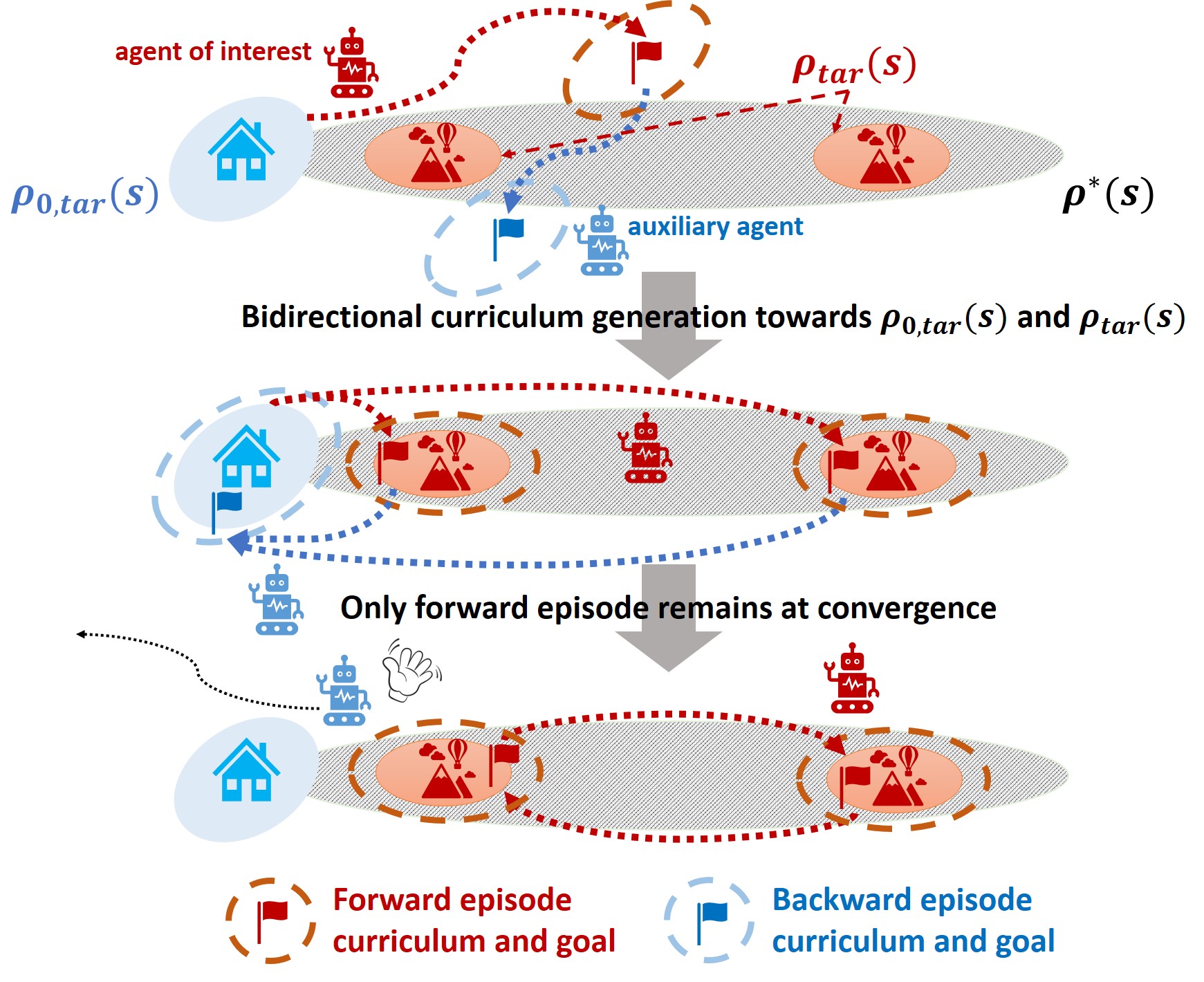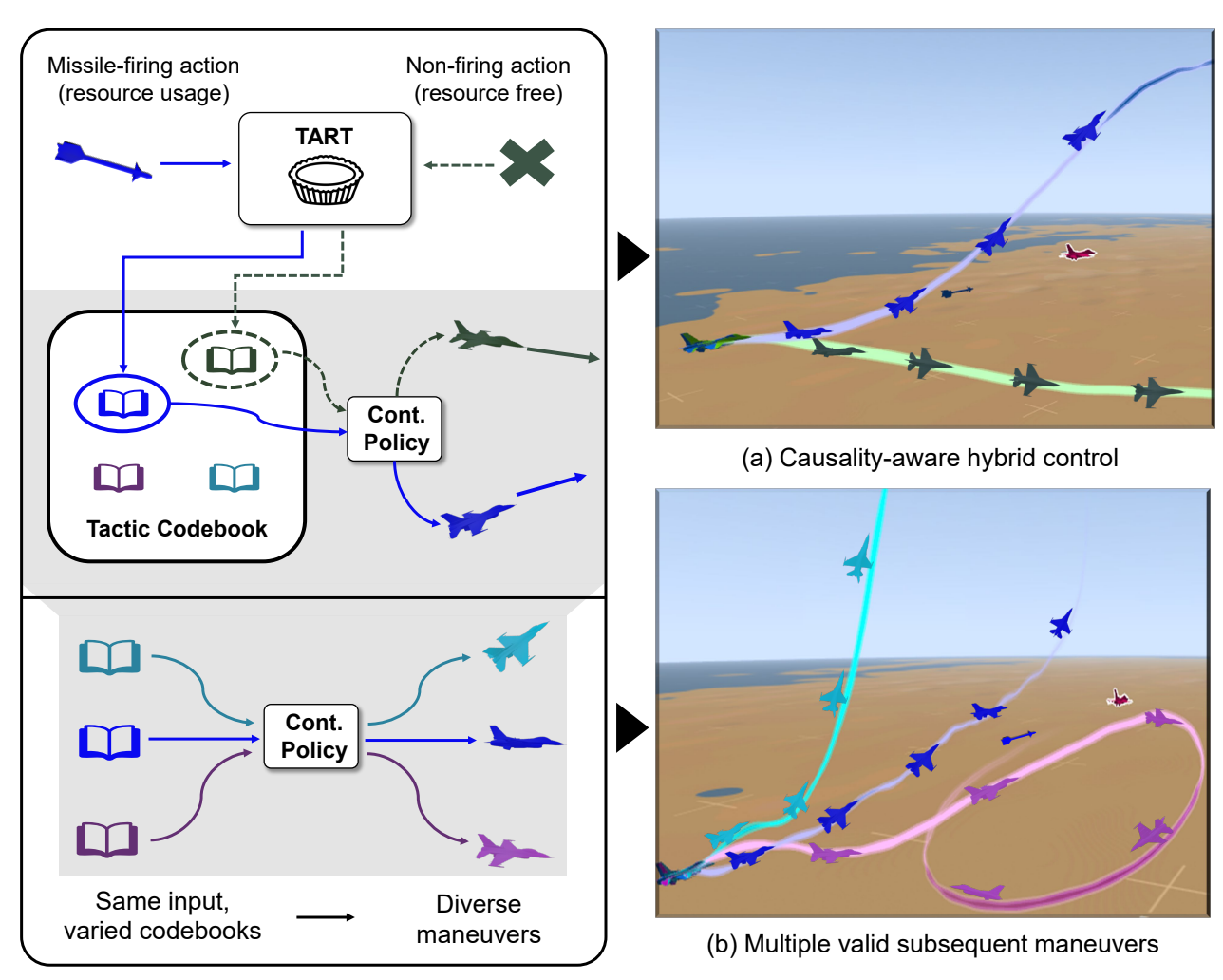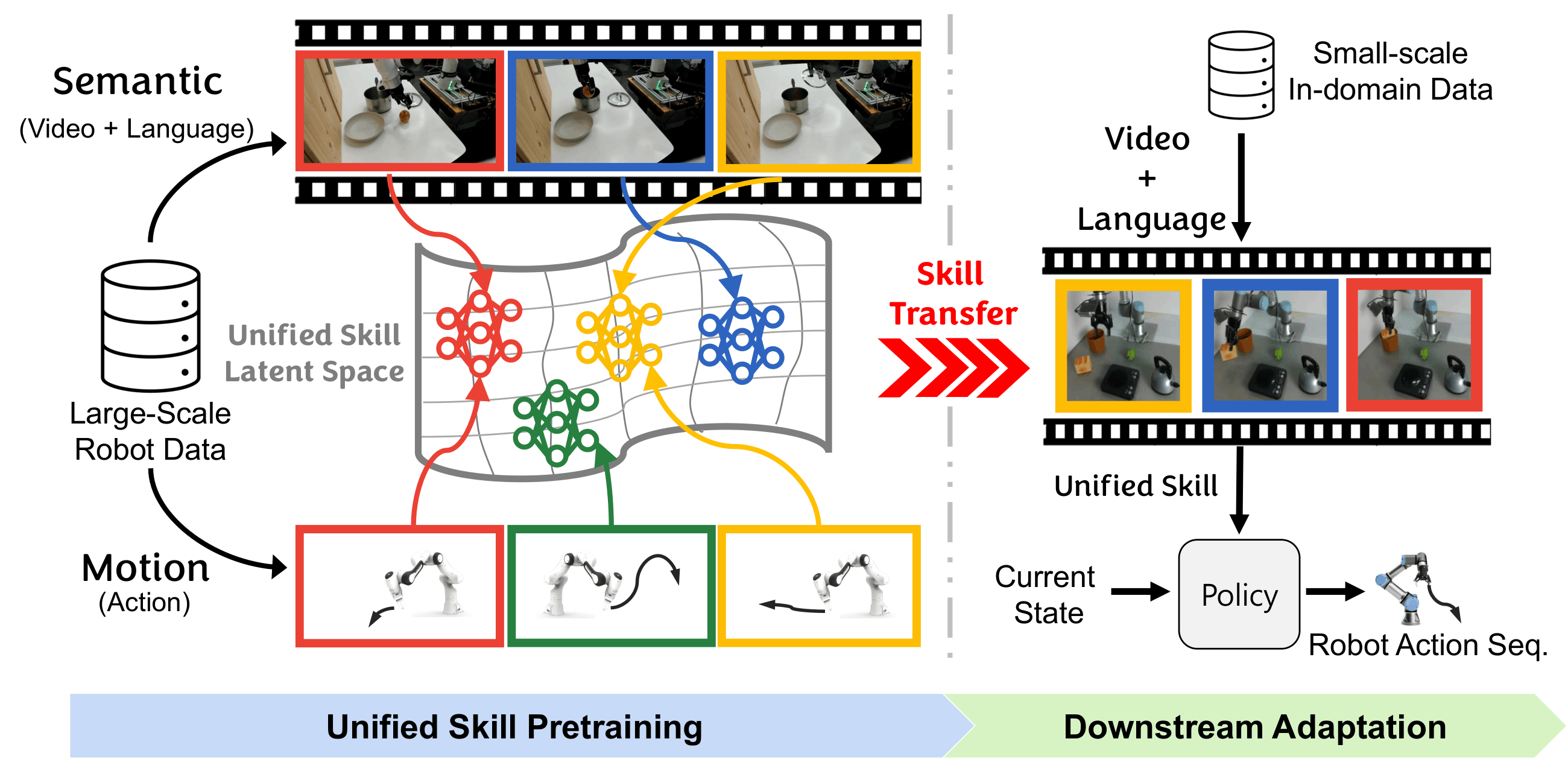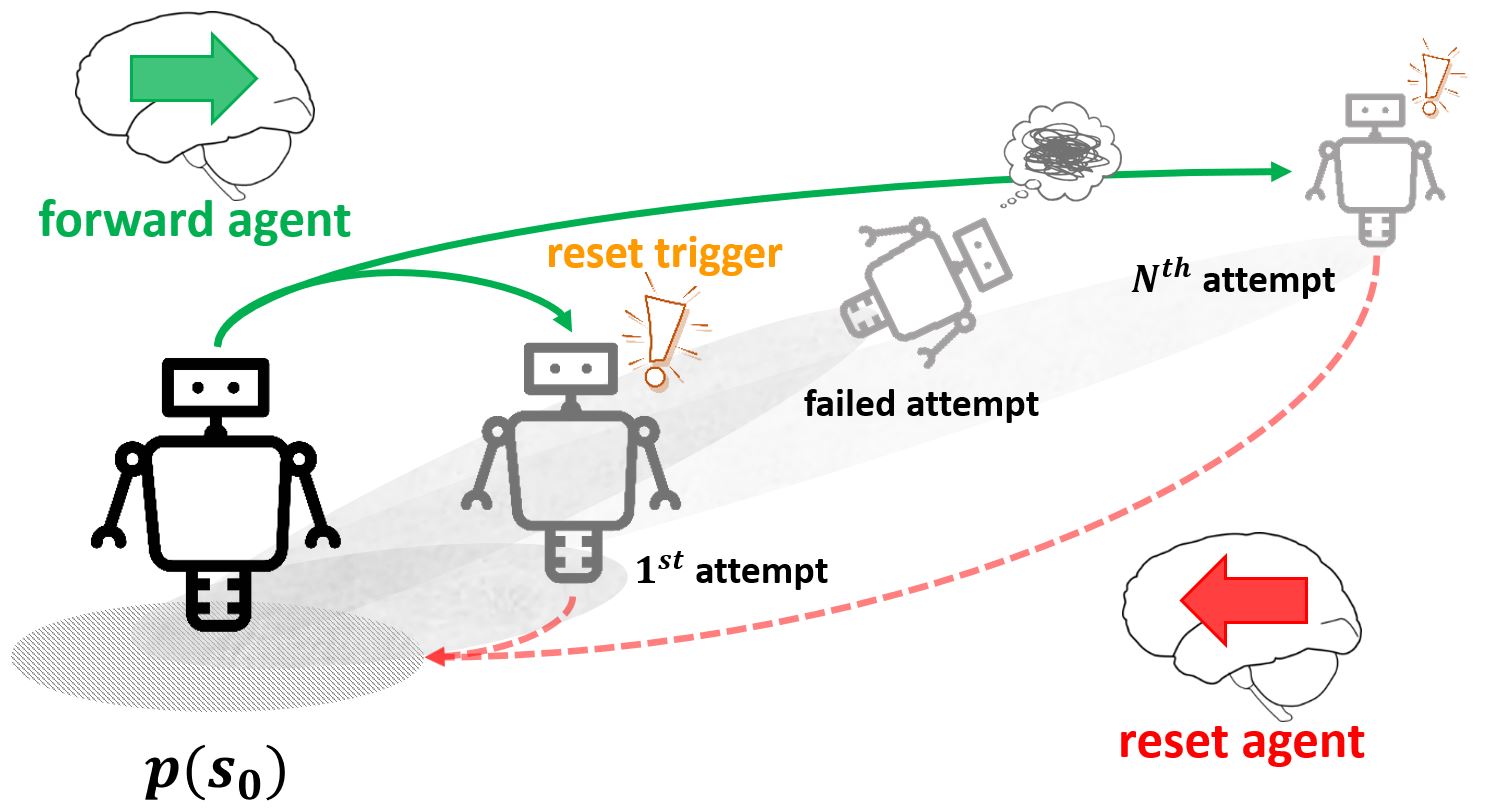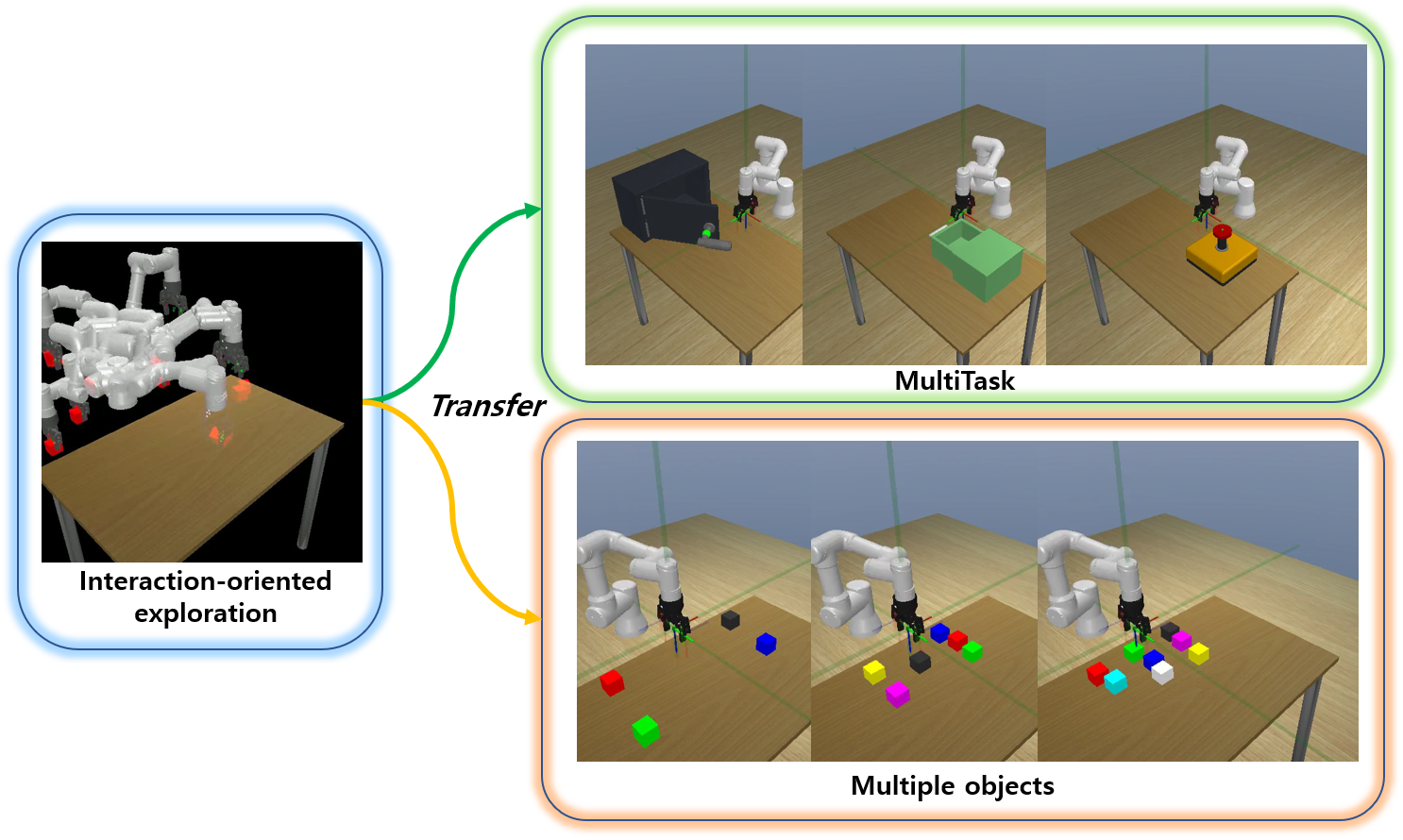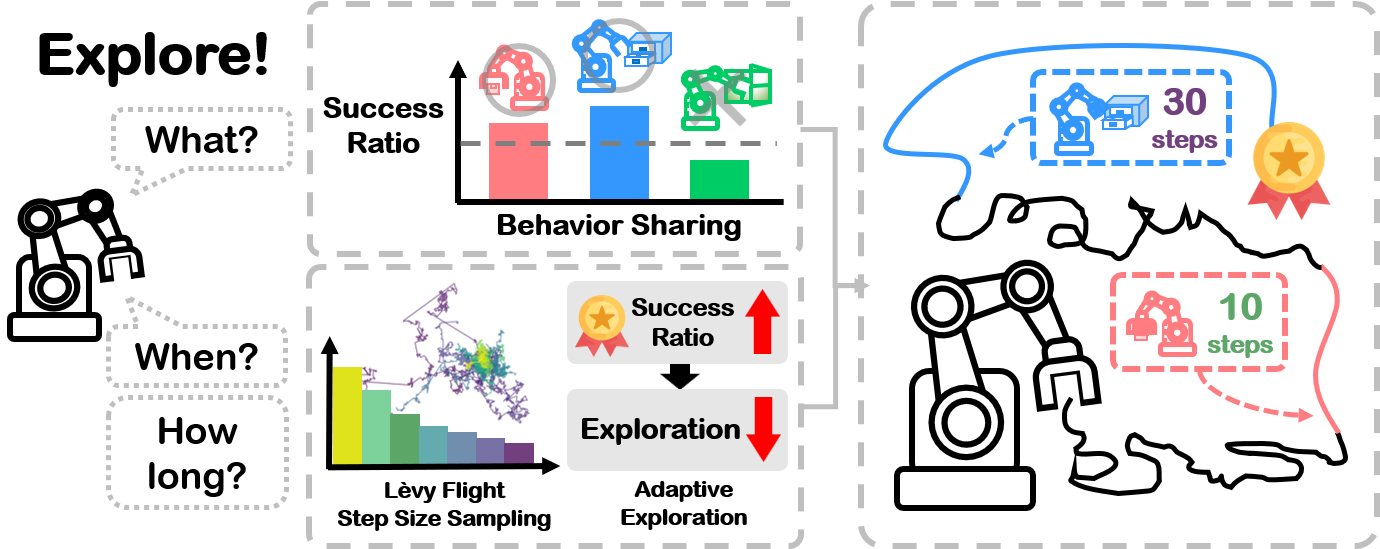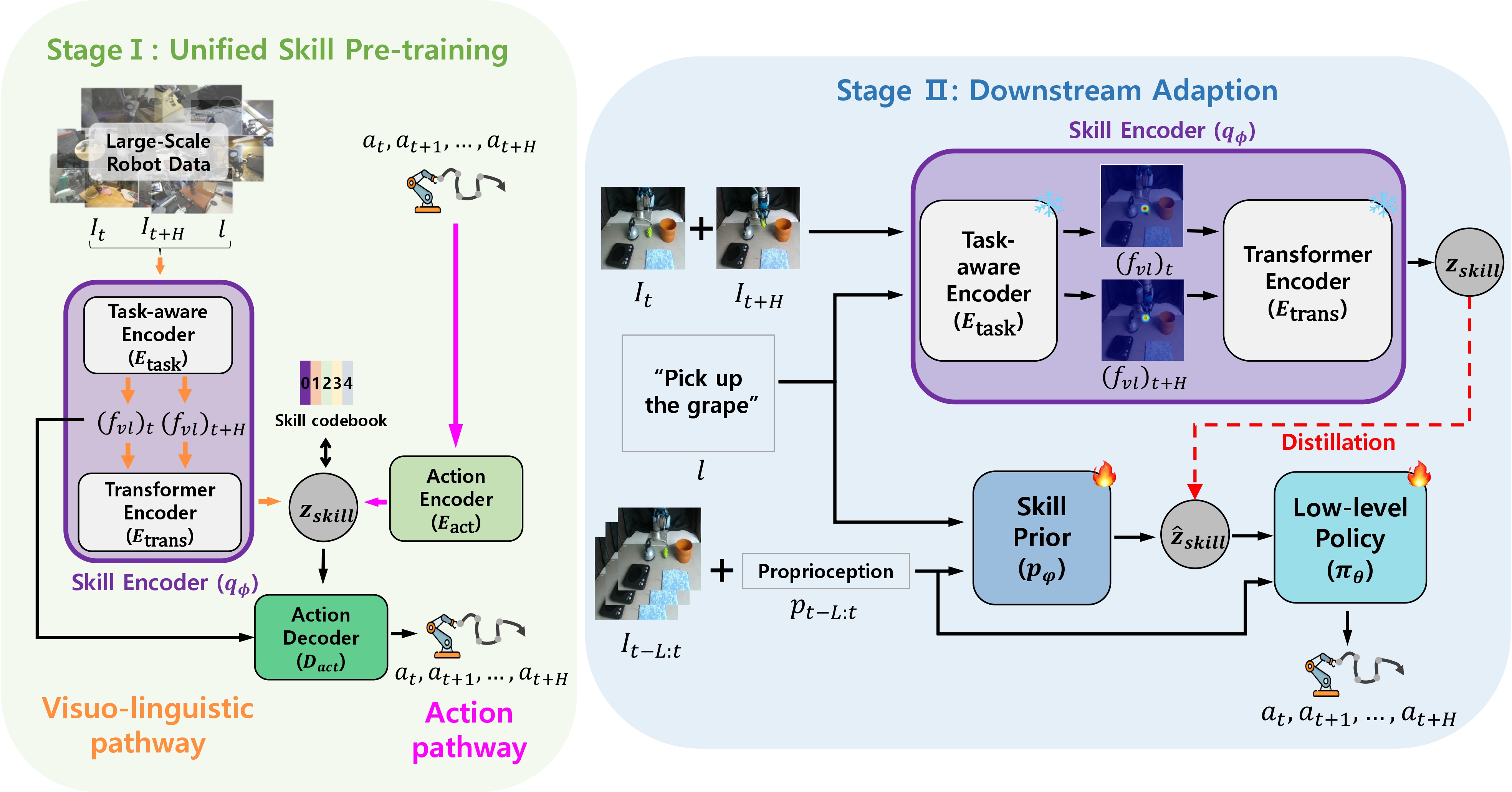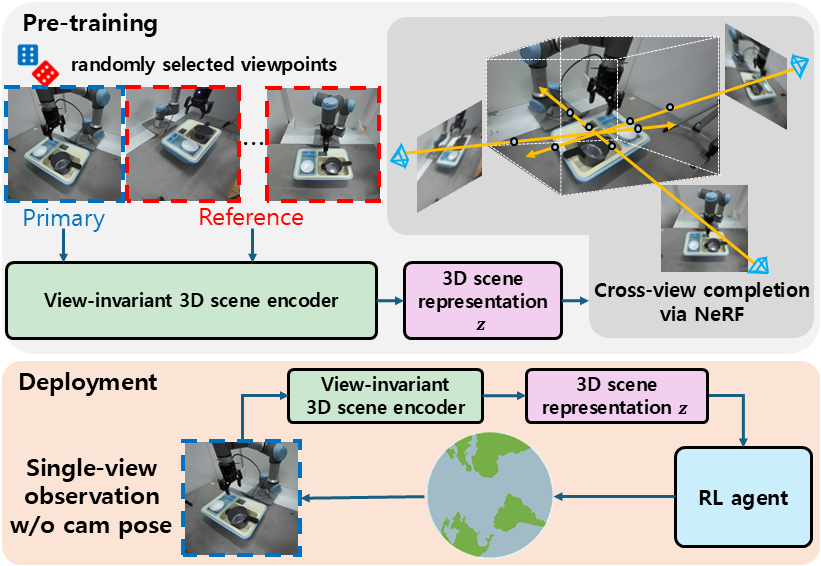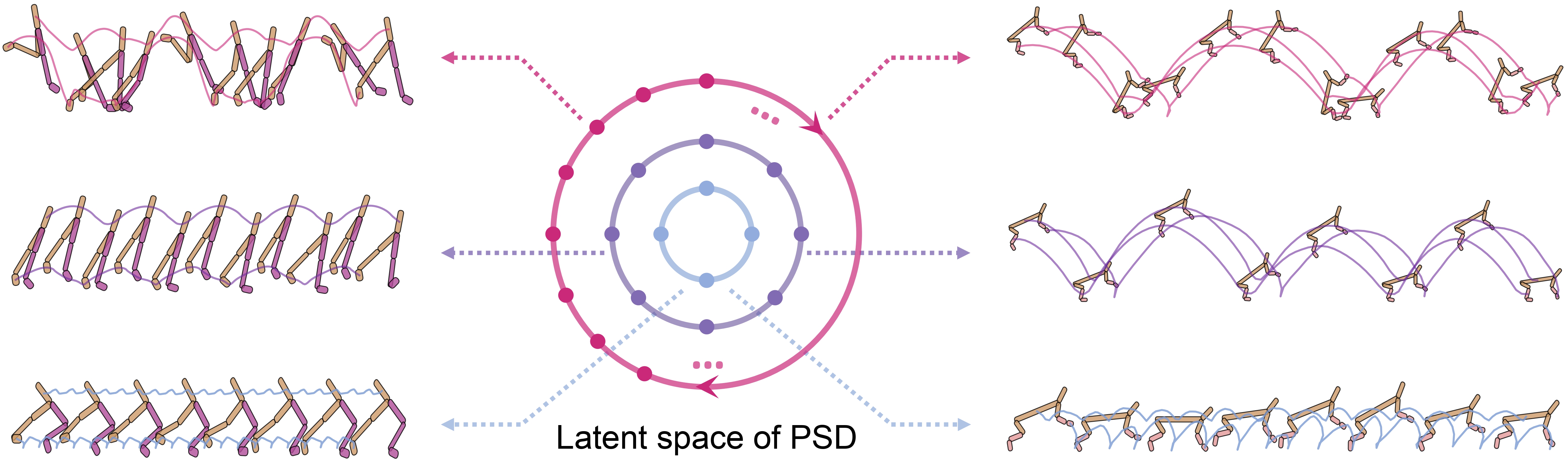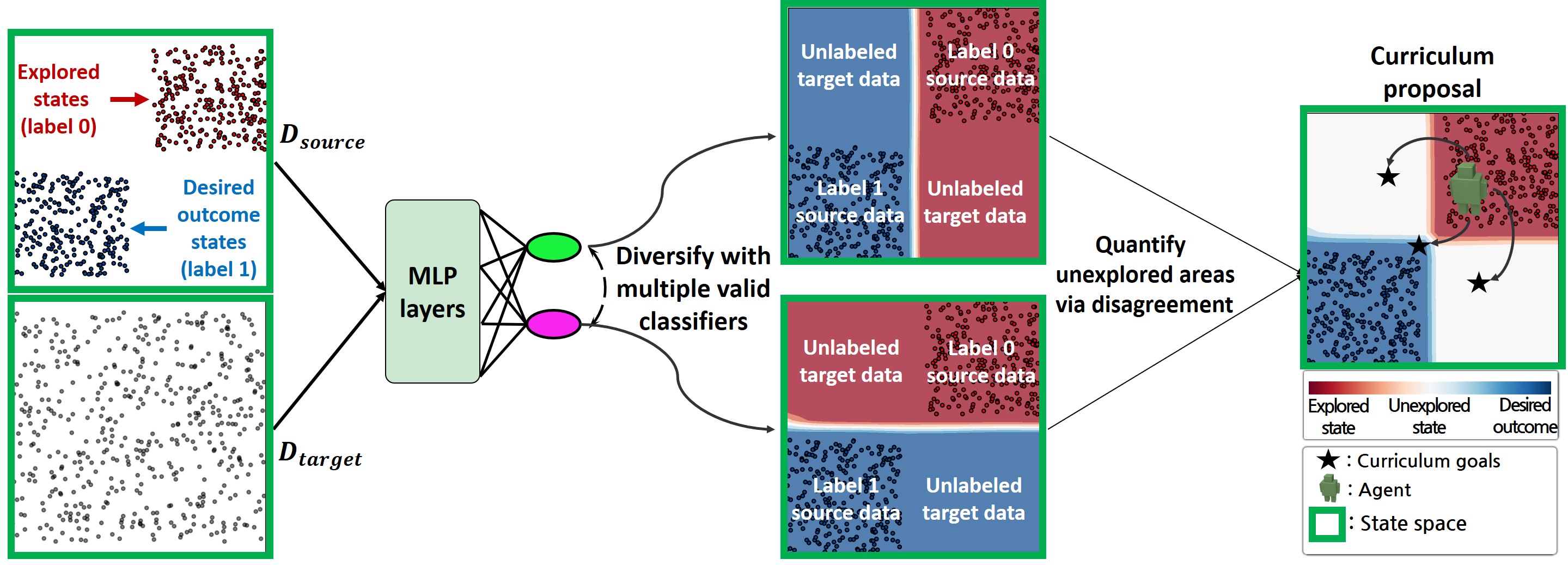
[NeurIPS 2023] Diversify & Conquer: Outcome-directed Curriculum RL via Out-of-Distribution Disagreement
Abstract: Reinforcement learning (RL) often faces the challenges of uninformed search problems where the agent should explore without access to the domain knowledge such as characteristics of the environment or external rewards. To tackle these challenges, this work proposes a new approach for cu...